AI Model Exploration
A short video exploring the MLOps features MLOps pipelines
Narrator: Let’s switch into data science mode. Models are special artifacts that require special handling. And Modelers, those folks who care about model care and feeding, have their own user experience, their own lifecycle tools, AI specific pipelines and direct access to Jupyter Notebooks.
Note: If you are not a trained data scientist say that to your audience. You might simply be a old school enterprise app developer but that is OK because when working with LLMs is much easier than having to train models from scratch.
Go back to component and the Overview tab
Click on RHOAI Data Science Project
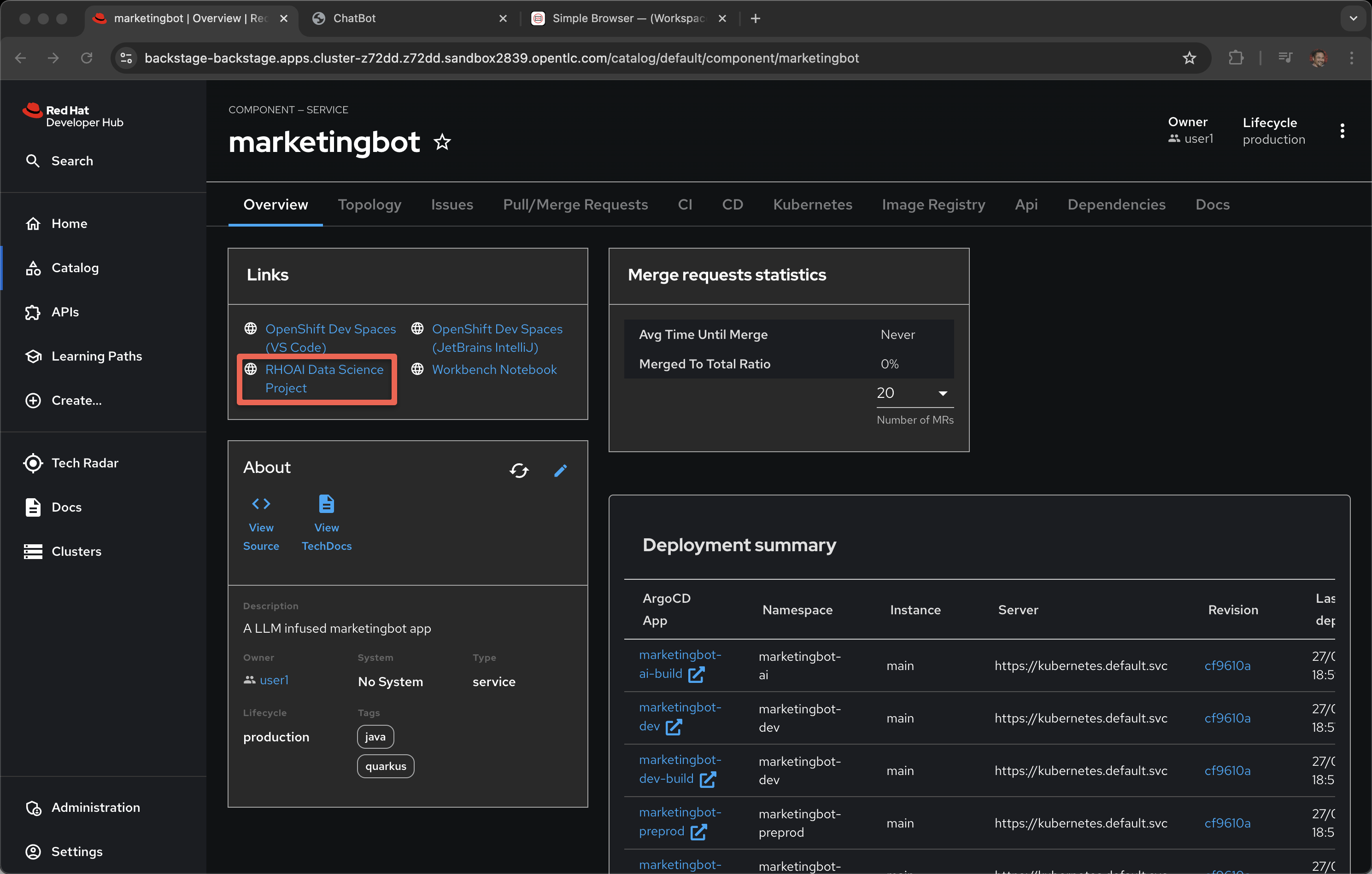
You may be asked to login, use the credentials provided by the demo system, the same user and password as you used for Developer Hub.
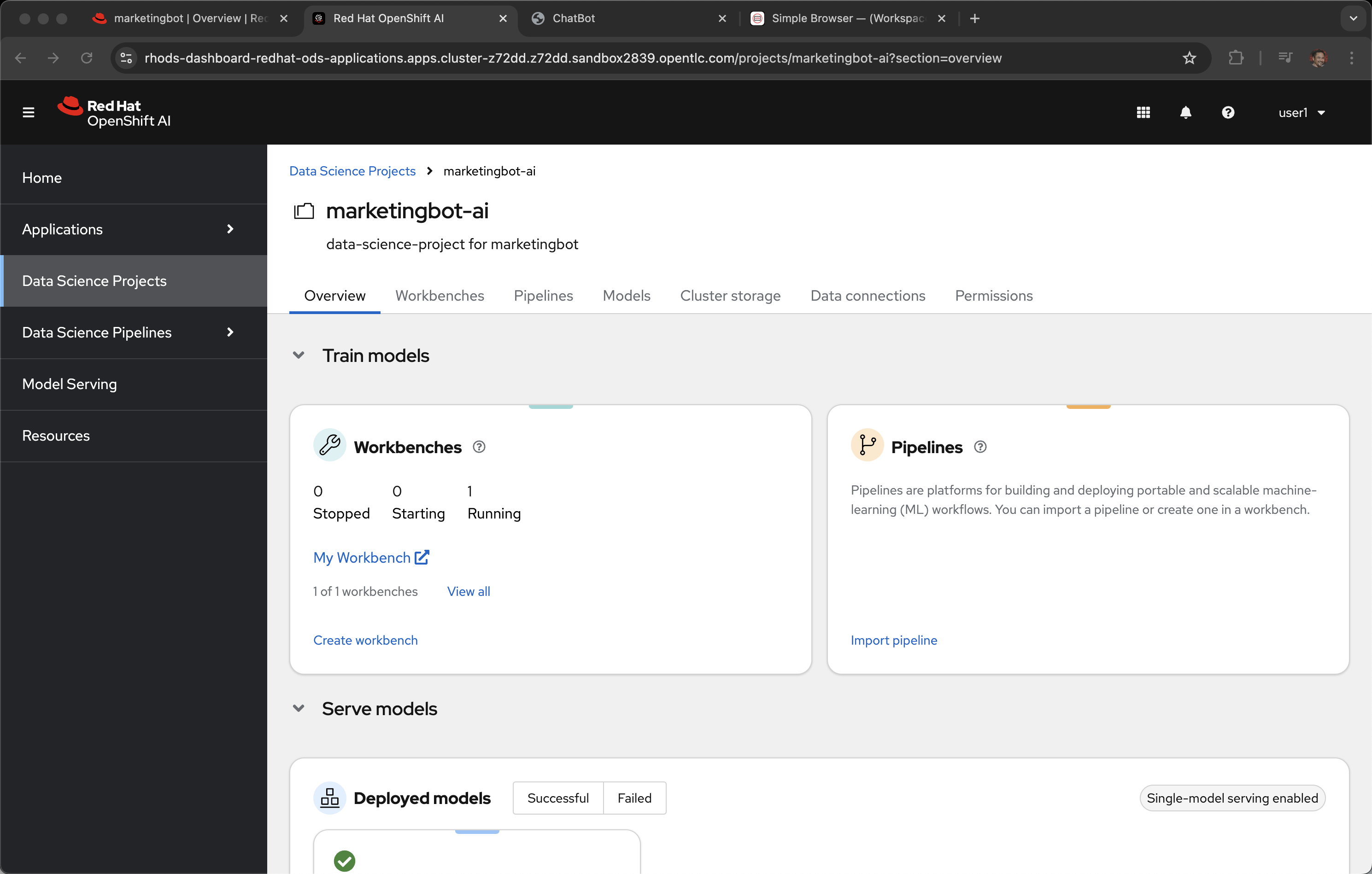
This is Red Hat OpenShift AI, an experience optimized for the AI/ML model curator, creator, maintainer, tester, etc.
The following is the AI+RAG response for "What is OpenShift AI?". More on the RAG demo in a another module.
OpenShift AI is an Operator that is available in a self-managed environment, such as Red Hat OpenShift Container Platform, or in Red Hat-managed cloud environments like Red Hat OpenShift Dedicated (with a Customer Cloud Subscription for AWS or GCP), Red Hat OpenShift Service on Amazon Web Services (ROSA Classic or ROSA HCP), or Microsoft Azure Red Hat OpenShift. It integrates various components and services, including the OpenShift AI dashboard, model serving, and other open source and third-party applications. The OpenShift AI dashboard provides a customer-facing interface to manage users, clusters, notebook images, accelerator profiles, and model-serving runtimes, among other things. Data scientists can use the dashboard to create projects to organize their data science work.
Sources:
Data Science Projects. The marketingbot-ai project was auto provisioned via gitops (ArgoCD) when the template was used earlier in the demonstration.
Workbench: A workbench is an instance of a development and experimentation environment for data science projects. It serves as an isolated area where you can examine and work with Machine Learning (ML) models, work with data, and run programs. A workbench is not always required, but it is needed for most data science workflow tasks such as writing code to process data or training a model. You can create multiple workbenches within a project, each with its own configuration and purpose, to separate tasks or activities. A workbench is created by selecting a notebook image, which is optimized with the tools and libraries needed for model development. Supported IDEs include JupyterLab, Visual Studio Code (Technology Preview), and RStudio (Technology Preview).
Sources:
Deployed Models: You can see the model server based on "vLLM custom" running, in a pod, the model that was originally downloaded from Huggingface.co.
Narrator: As a modeler, I like working in the world of Python and Red Hat OpenShift AI gives me self-service access and the Workbench gives me instant access to a properly configured Notebook.
Workbench
Open My Workbench
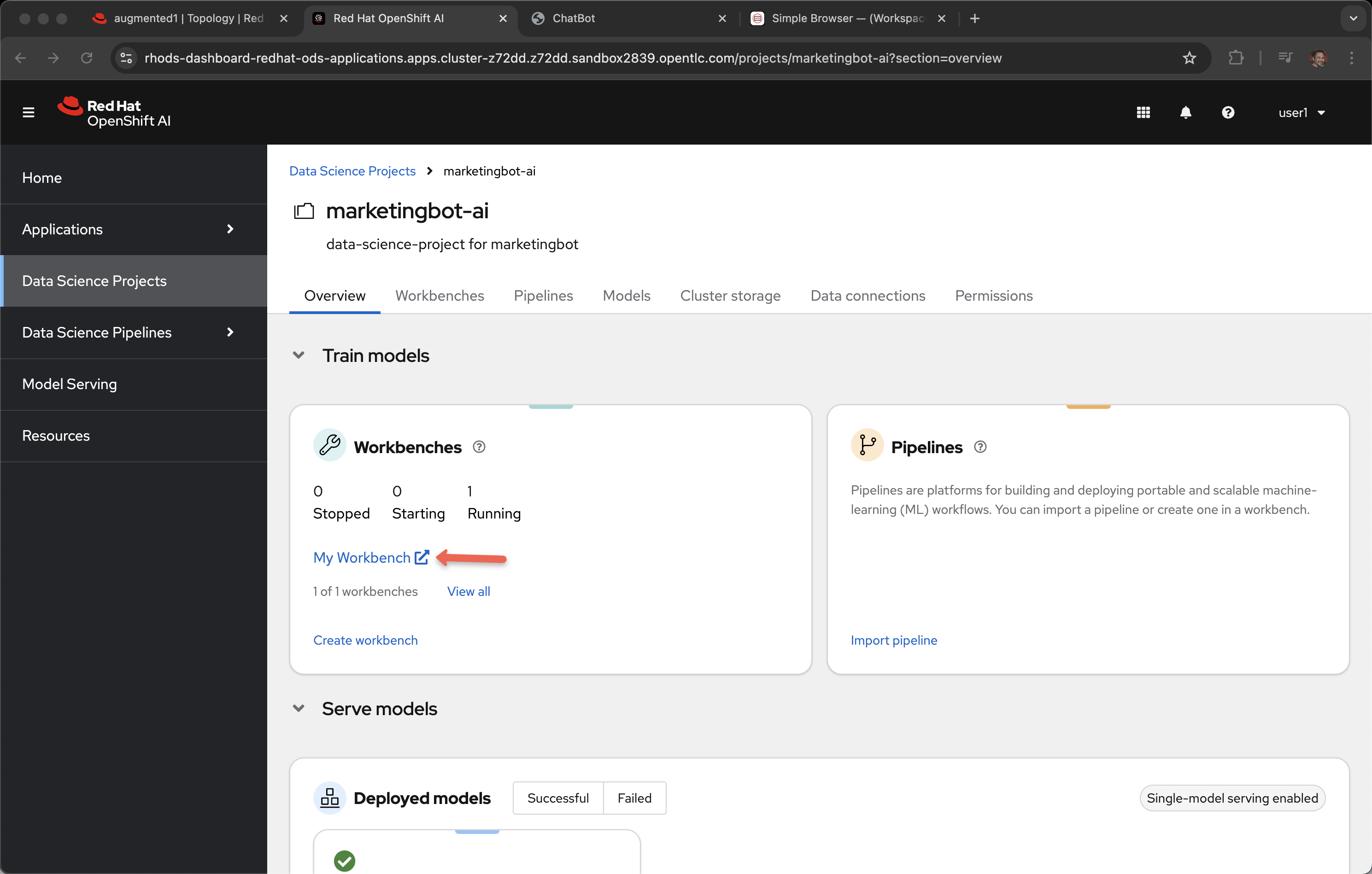
You may have to login in again.
And Authorize Access by clicking Allow selected permissions

Narrator: Now I am in a Jupyter Notebook, run as a container, as a pod, on the OpenShift cluster. Where the underlying container image has been properly configured with the appropriate versions of python and the needed libraries.
Double click on the folder check-confidence-self-hosted-llm to expand it out. And double click on test_response_quality.py
Narrator: Large Language Models (LLMs) are typically downloaded from the Internet (or used as SaaS endpoints via things like OpenAI.com’s ChatGPT) and do not require training from scratch. A LLM can be augmented and/or fine-tuned but that is out of scope for this introductionary demonstration.
One common thing to help manage the curation and lifecycle of a private LLM is to have test scripts and a recurring pipeline that measure things like a model’s performance against some test cases as seen in test_response_quality.py
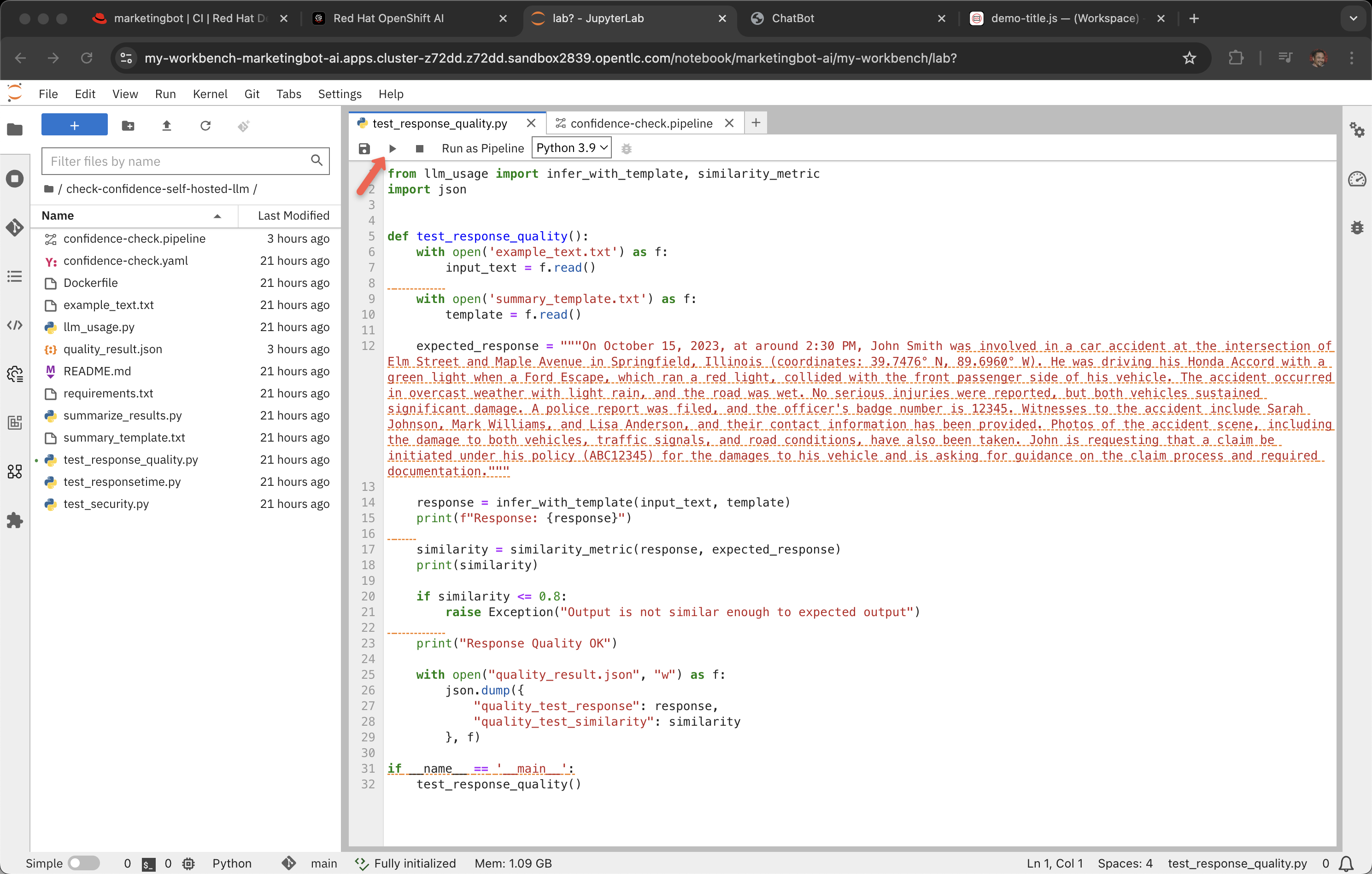
This code will print out "Response Quality OK" if the similiarity check is not less than or equal to 0.8
Note: It does some times fail this test, you might lower the number to .7
LLMs rarely return identical strings therefore the similiarity test is a way to deal with the varying responses.
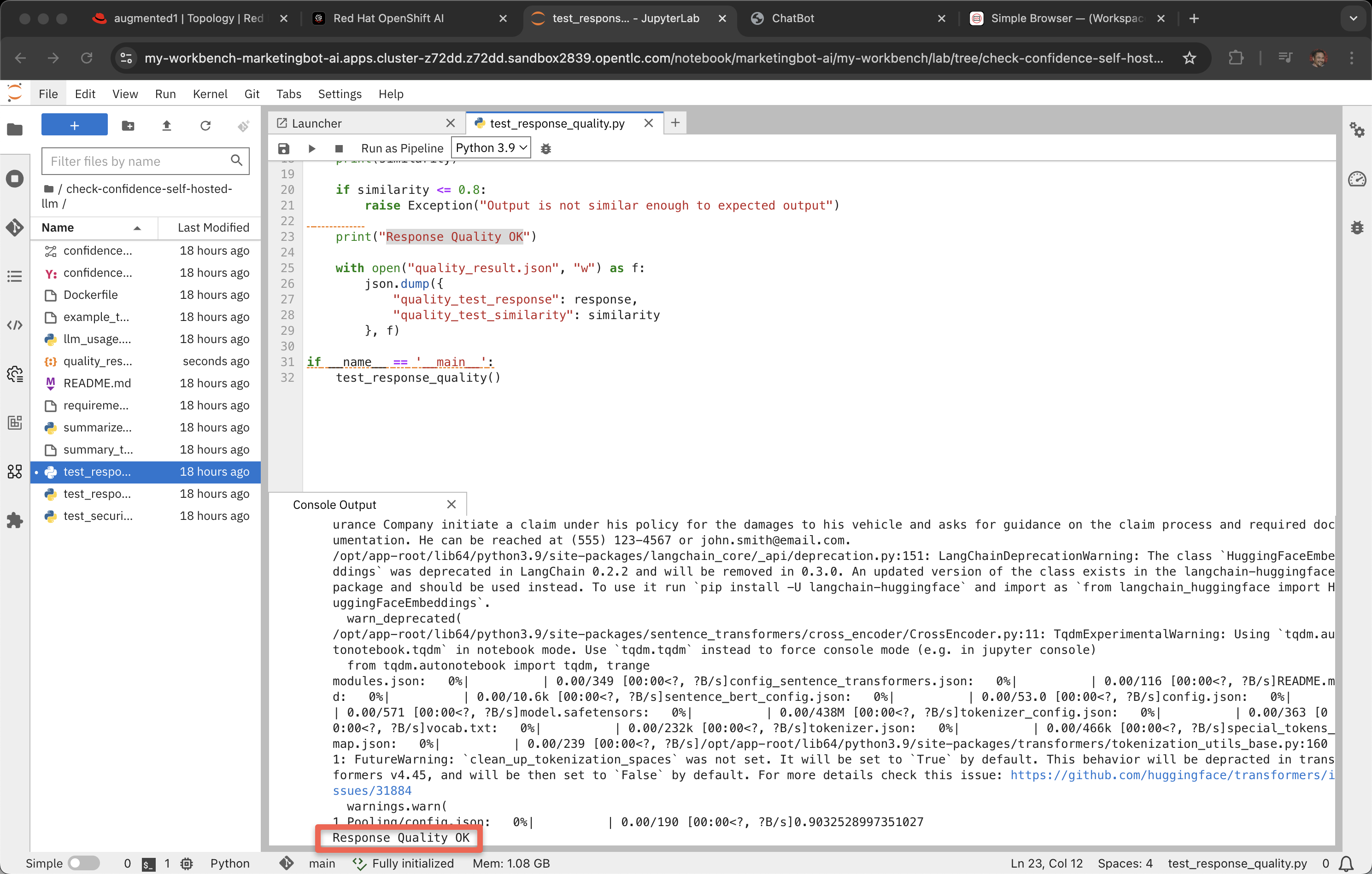
Pipeline
Double click on confidence-check.pipeline
Narrator: A MLOps pipeline, based on Kubeflow, can be used to create a scheduled set of tests against the LLM. In the case of the confidence-check.pipeline, it tests for quality, response time and also has a simple identity verification step.
Click the "run" button
Click OK
Click Run Details
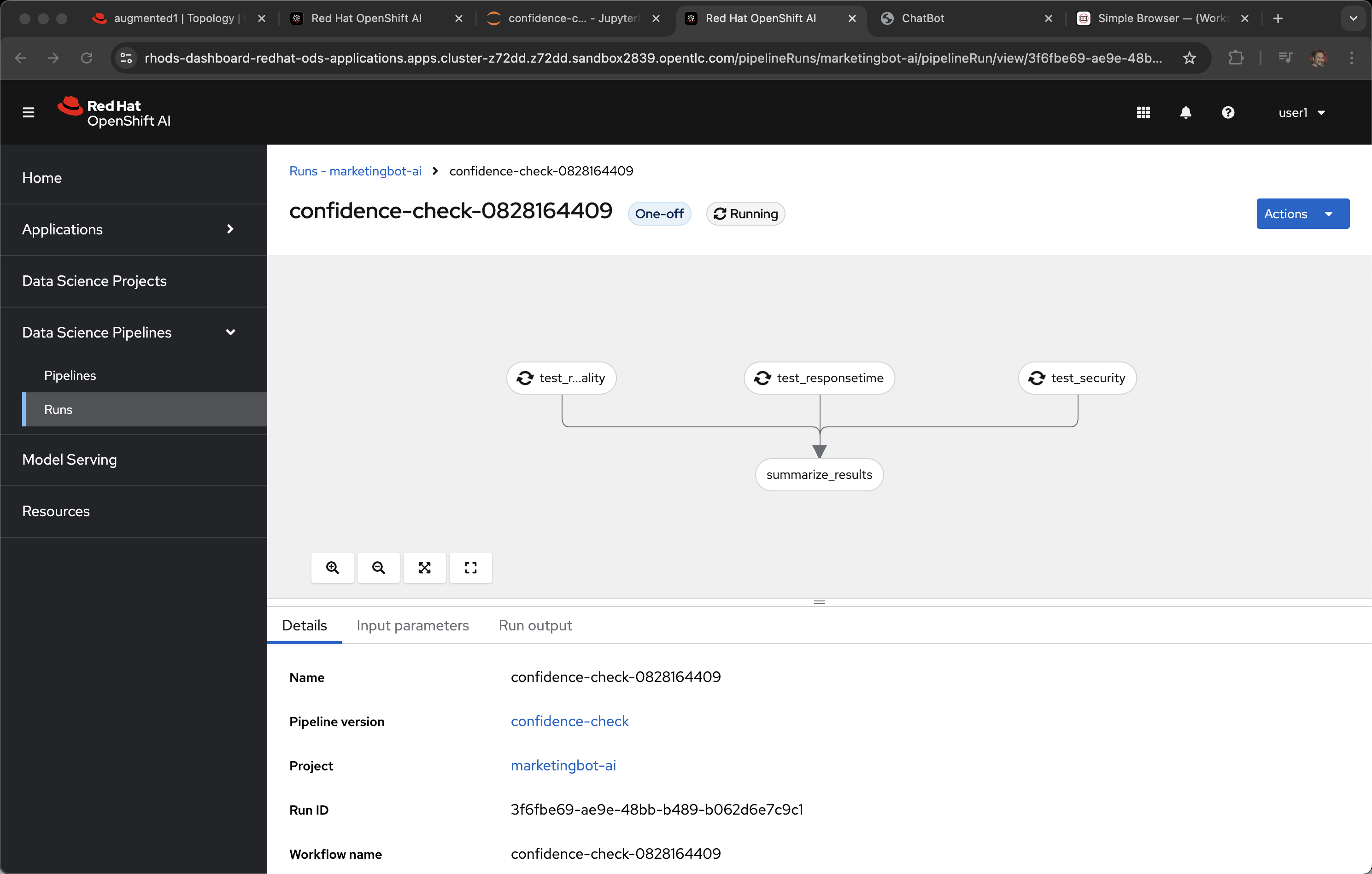
And if you do get a failure on the quality test, it is very likely to be that .8 bar is too high. LLMs have non-deterministic their responses are almost always unique per invocation, even if the input prompt is identical.
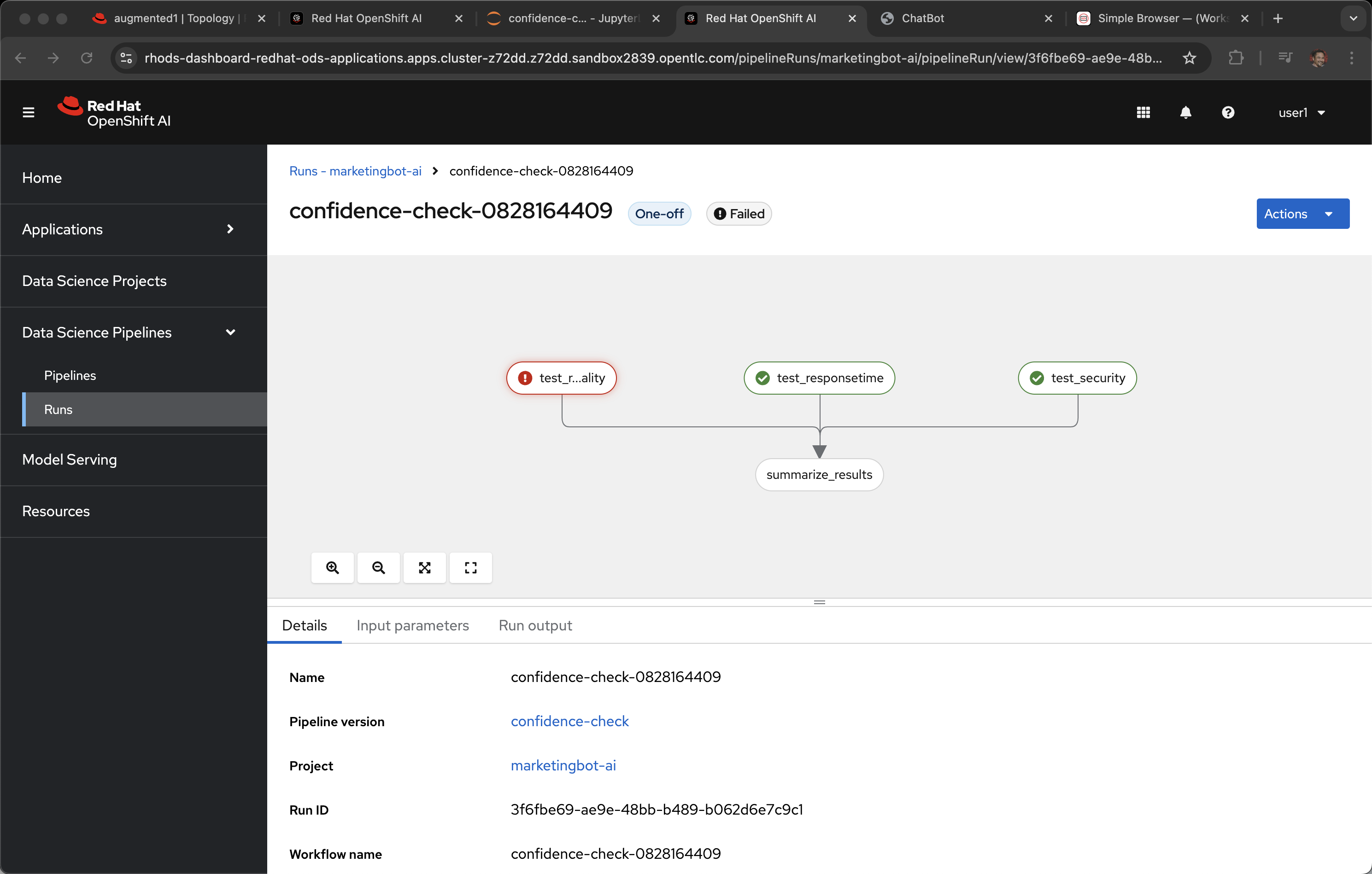
If this occurs you can return to the Notebook and change .8 to .7 in test_response_quality.py and run the pipeline again.
Model Serving
Narrator: Let’s briefly look at the model serving capability.
Click on Data Science Projects and marketingbot-ai
Click on Models
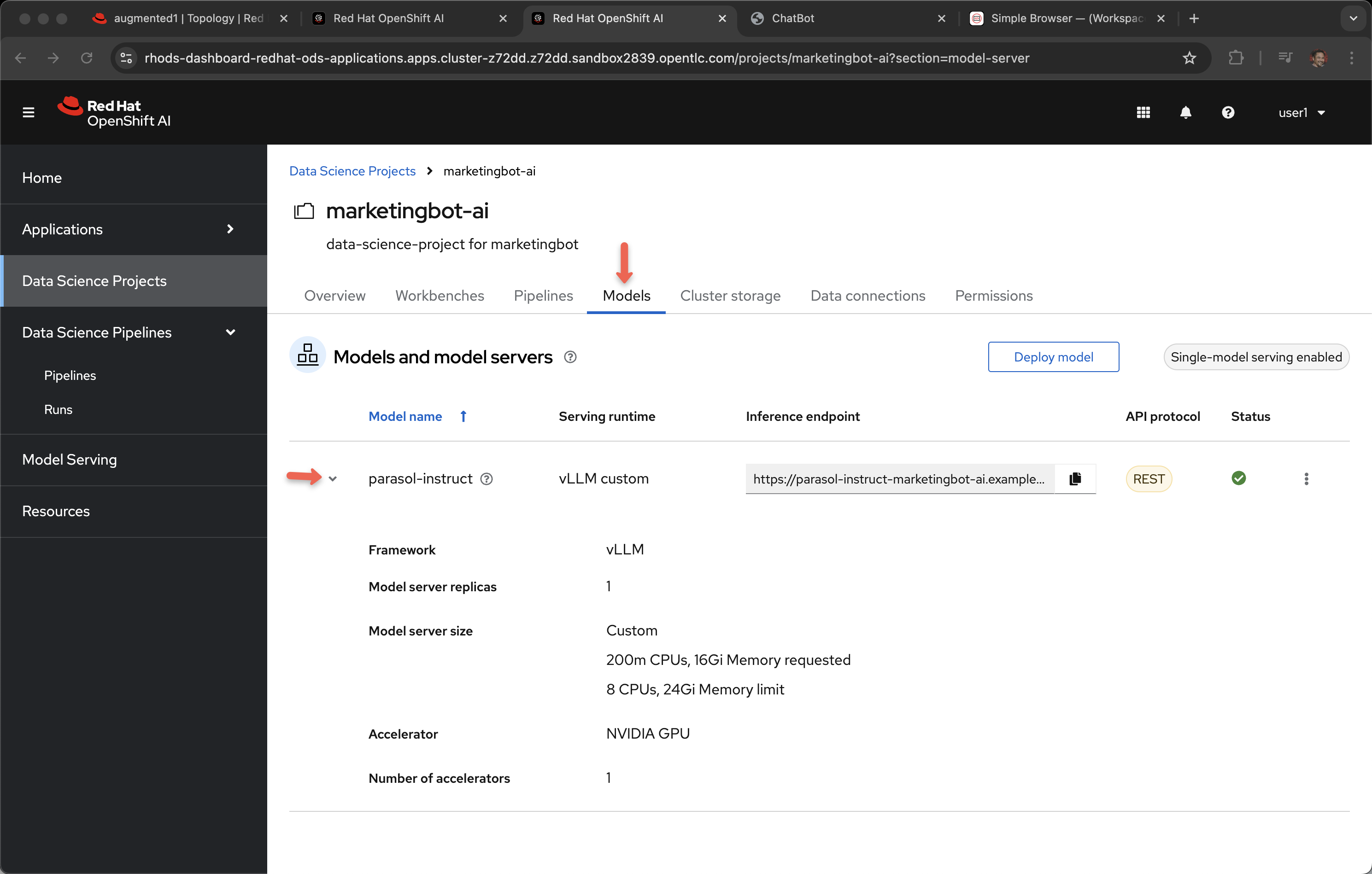
The parasol-instruct model was selected when we used the template wizard.
vLLM custom was defined in the gitops repository for automation.
Note: At the time of this writing, the Inference endpoint is inaccurate when using a gitops-based approach for provisioning the model server.
This specific model server also needs a fair bit of memory, CPUs and a NVIDIA GPU. This means it must be scheduled to a OpenShift worker node that has a GPU, which all that happens automatically.
Click on the ellipses and select Edit
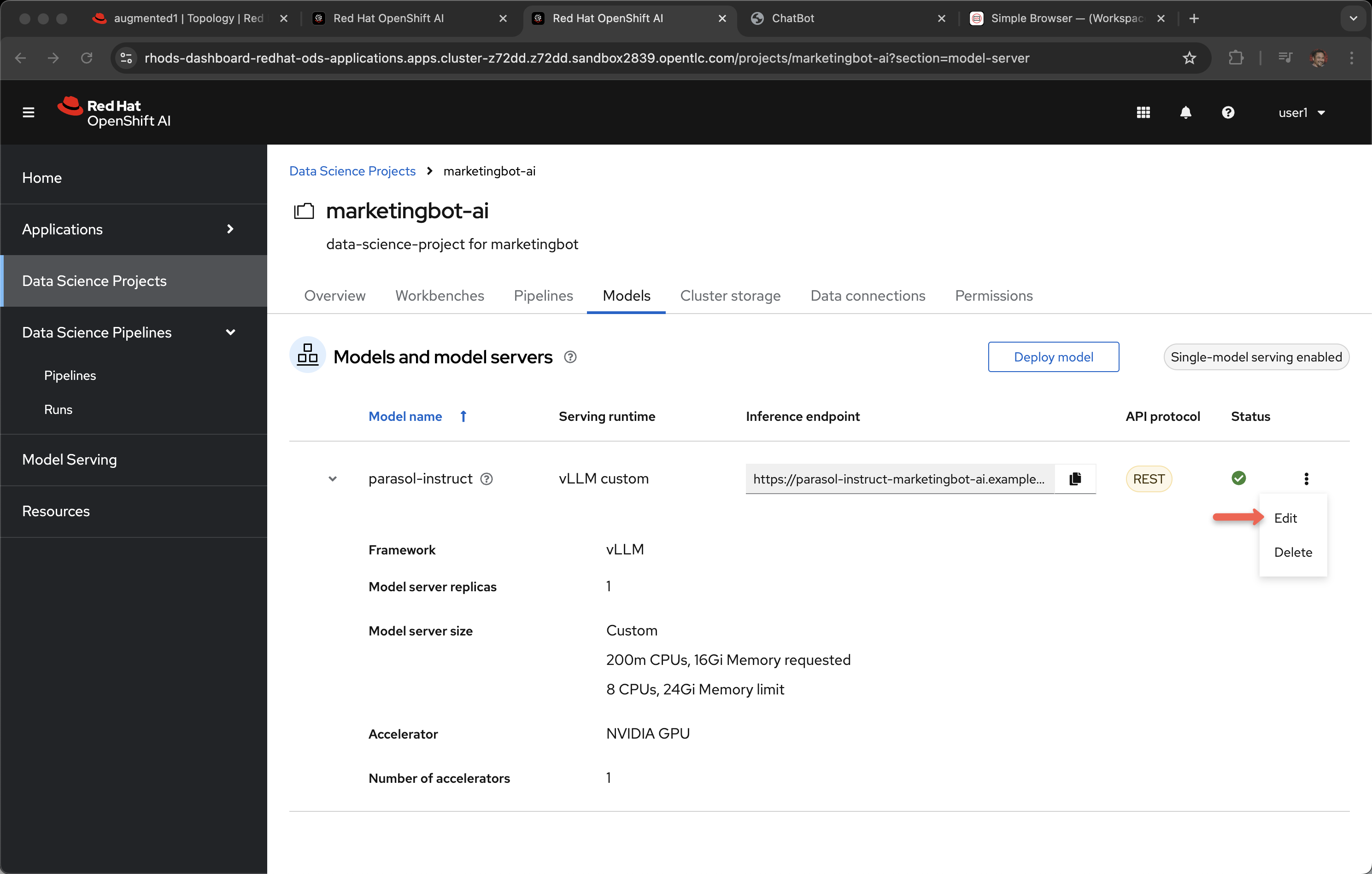
Narrator: Now, how did this model come to life? If we scroll down toward the bottom of the screen you can see the settings for cores, memory and GPU but also the data connection. This connection is to an S3 bucket called parasol-instruct.
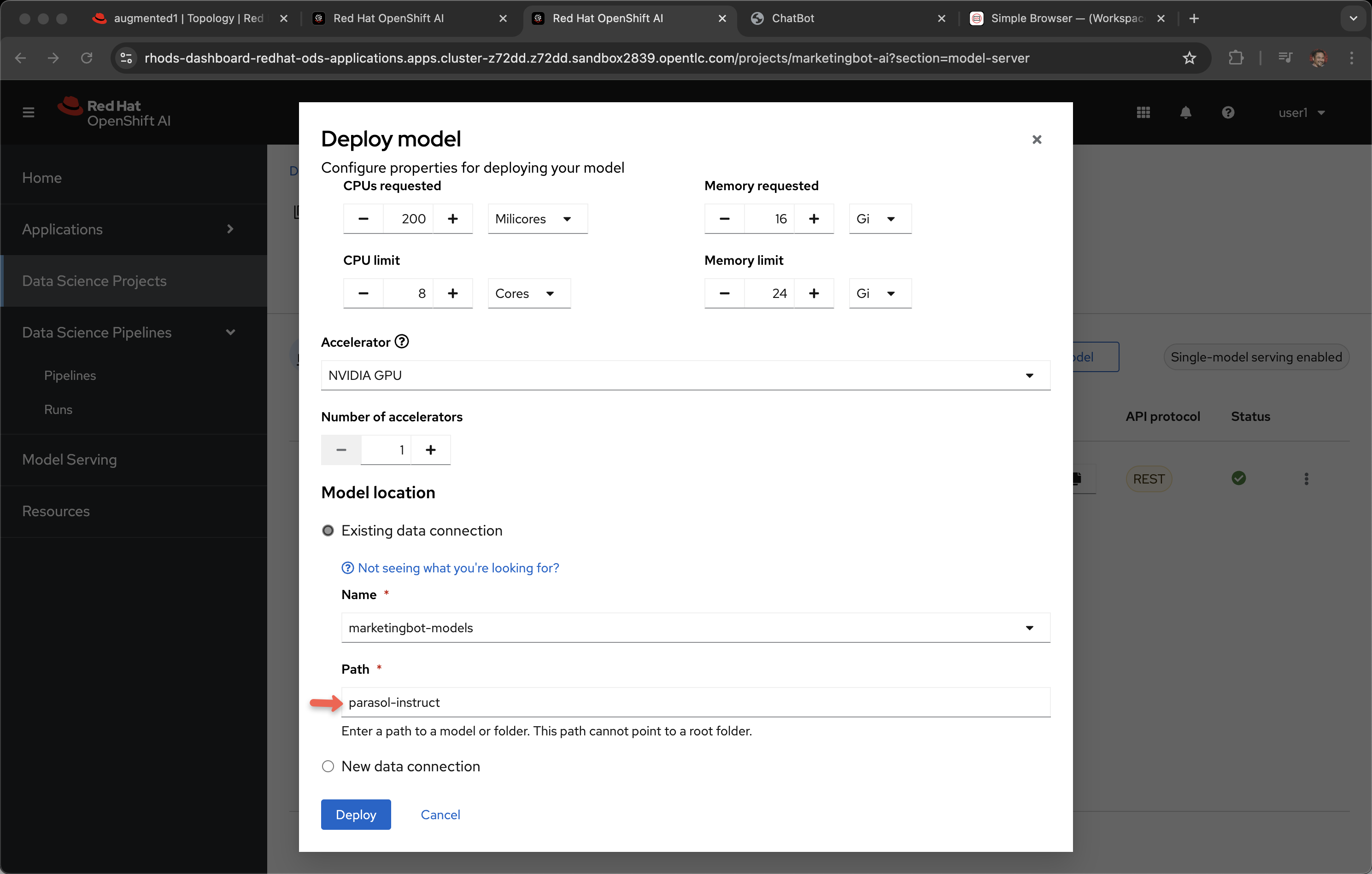
Click Cancel as we do not need to make any changes
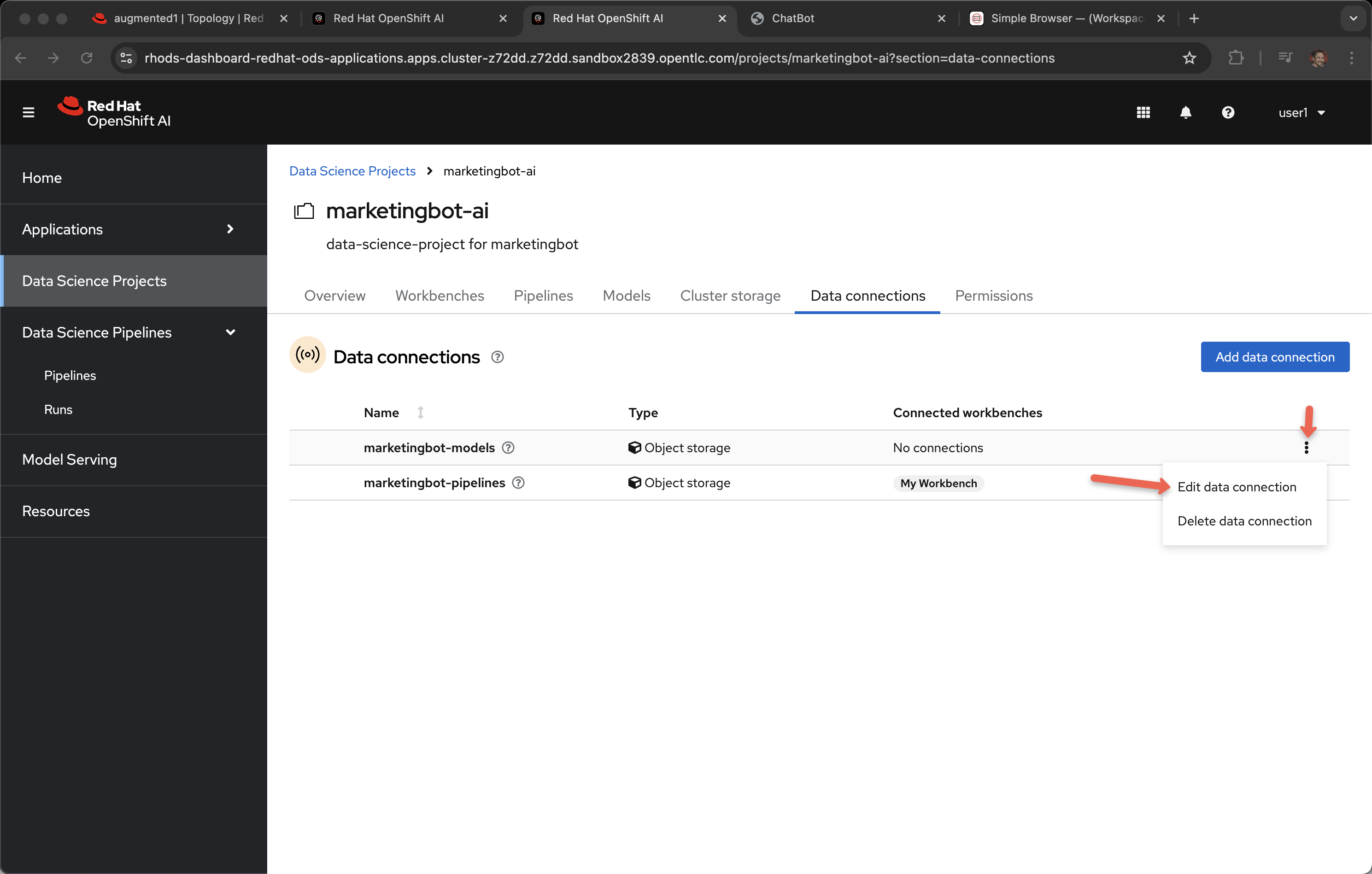
Click Data connections and Edit data connection for marketingbot-models.
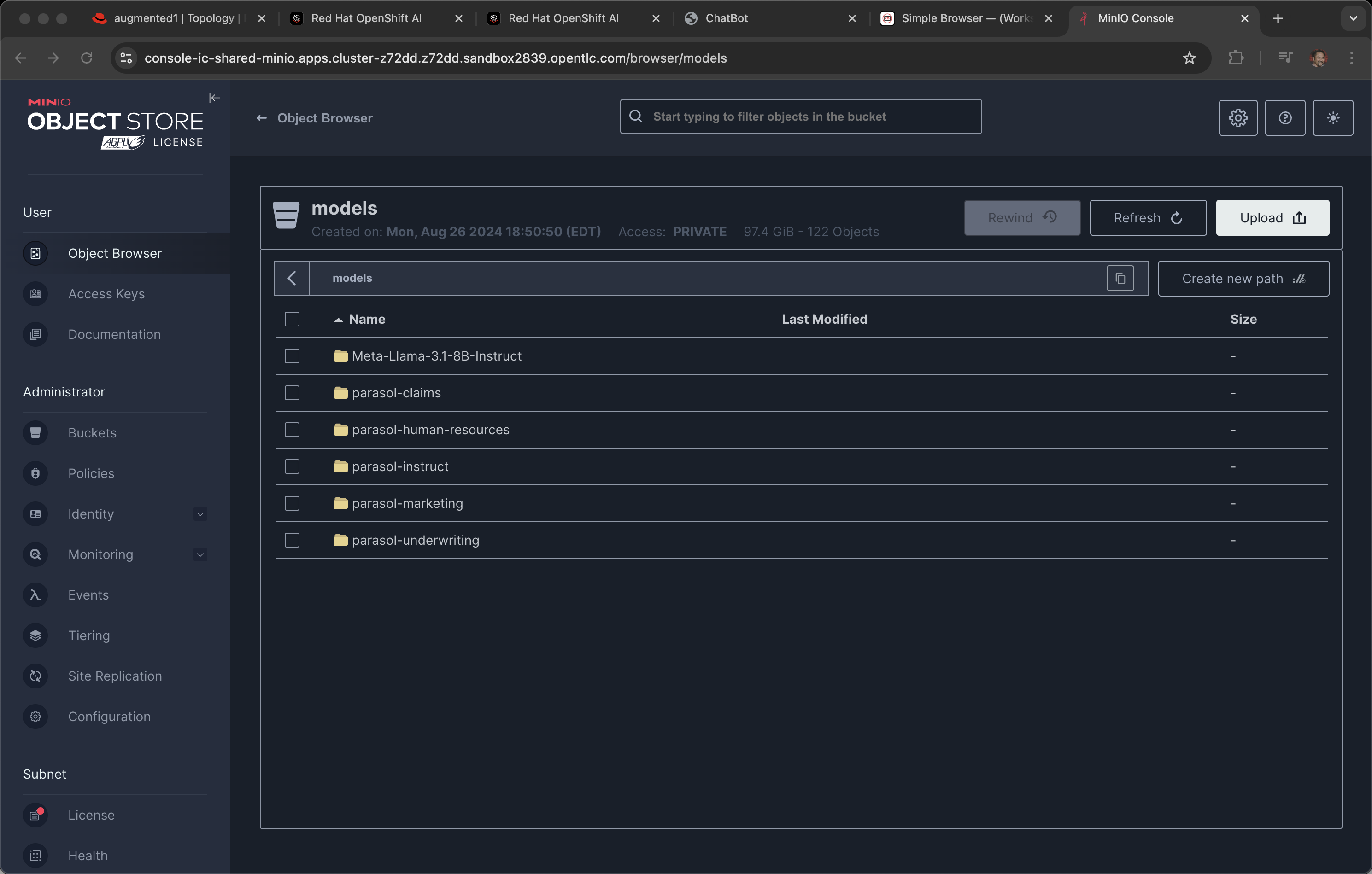
You can see the endpoint is mapped to Minio, an in-cluster, S3 solution.
And the bucket is called models.
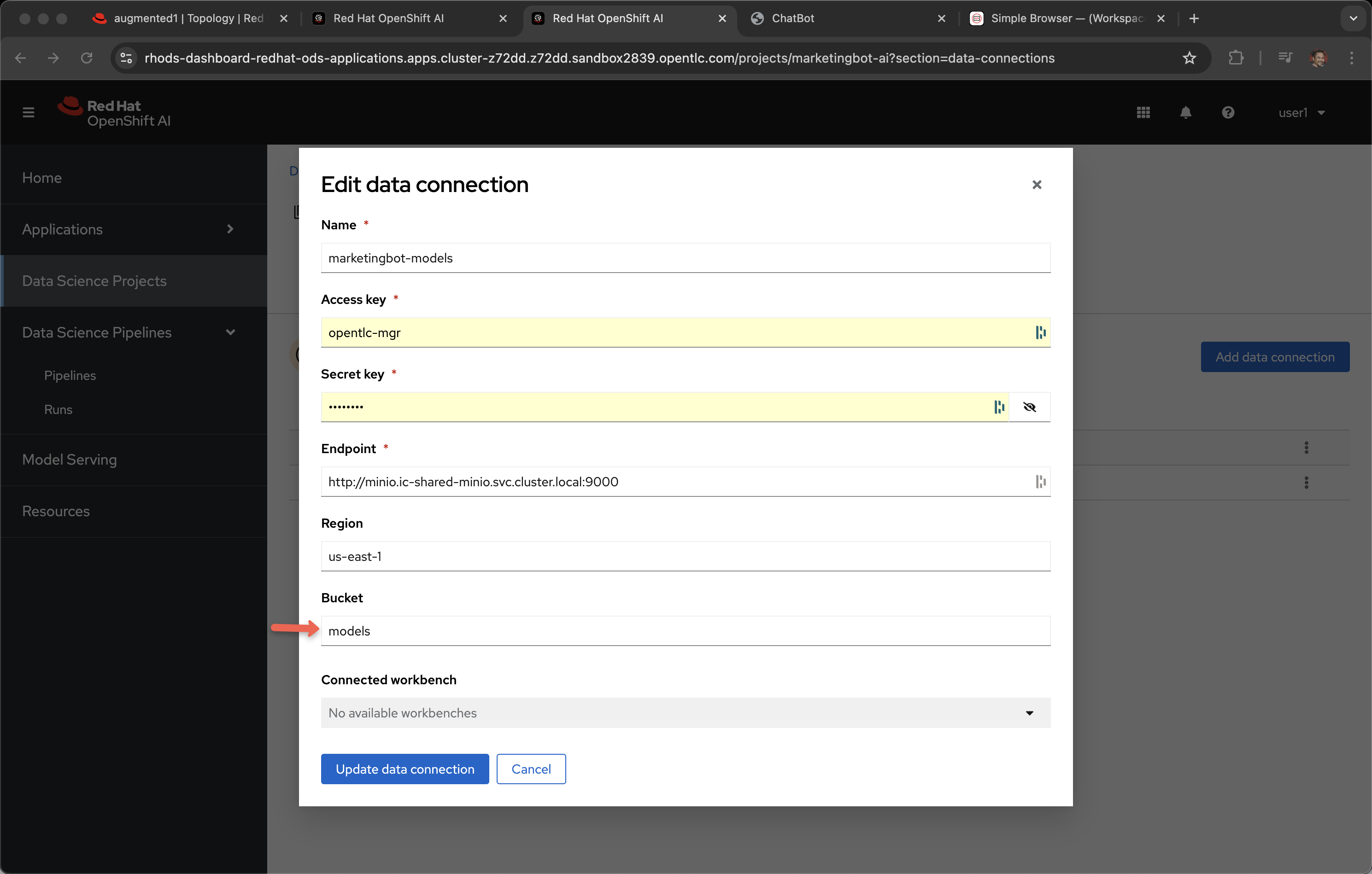
These models are simply sitting in storage and are visible using your S3 browser, in the case of Minio, it has a nice GUI for viewing the artifacts.